比特币中Txid和Txhash的区别
在比特币中为什么有些交易的txid 和txhash相同,但是有些交易的txid 和txhash又不同,这其中到底是为什么?
这是因为比特币中隔离见证(Segregate Witness, segwit)技术的引入导致的这个问题.
- 如果一笔交易是segwit 的交易,那么这笔交易计算txid的过程中不包括witness data,但是txhash是在计算hash的过程中包括witness data. witness data只的是交易中ScriptSig(交易中用户的签名和公钥).
- 如果一笔交易是非segwit的交易,那么txid 和txhash是相同的.
隔离见证的引入参见比特币bip141提议.
bip141提议计算交易的hash时, 将signature data排除在外, signature data就是上文提到的witness data.
在比特币交易的input中提供的是txid,为什么把witness data排除在外呢?这是因为一笔交易中的输入部分有效的签名有多种形式,恶意节点收到一笔交易T1的时候,可以对交易的签名进行修改,修改之后签名仍然合法,但是整个交易的hash却发生了变化,假设变为了Tx2 恶意节点再将这个交易广播,如果其他节点接受了Tx2并且打包上链,那么Tx1就无法上链,此时发出Tx1的人无法查询到自己的交易上链,接收者让发送者再发送一次交易,这就会导致接收者多次接收交易.
为什么需要隔离见证
这里涉及到交易延展性问题,具体隔离见证的解释,可以参考如下链接:
第二个链接,知乎上前几个回答不靠谱,隔离见证最好的是用来解决交易延展性攻击问题.




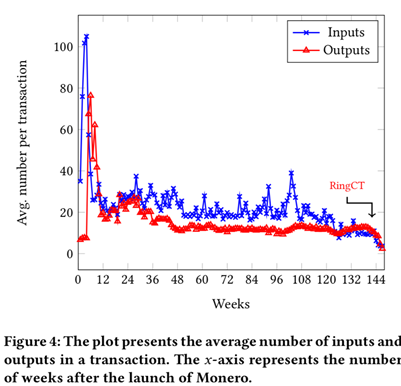
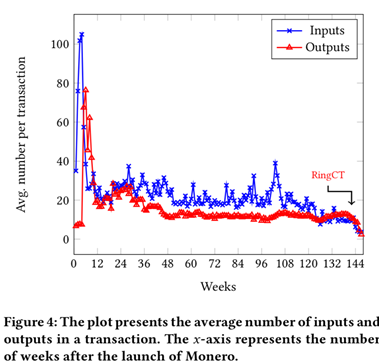
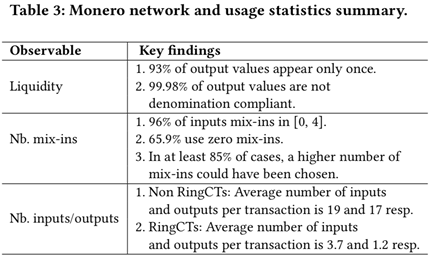
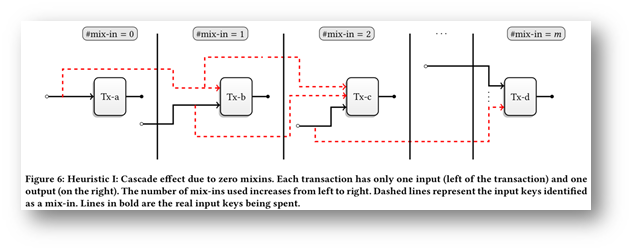





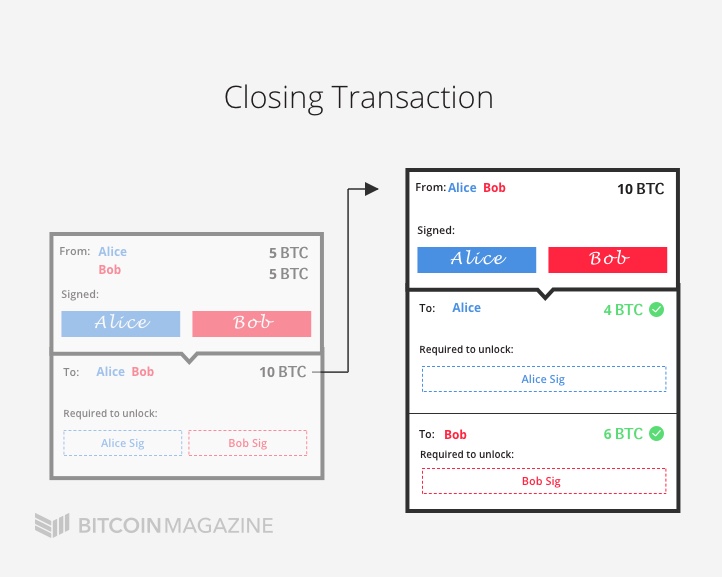
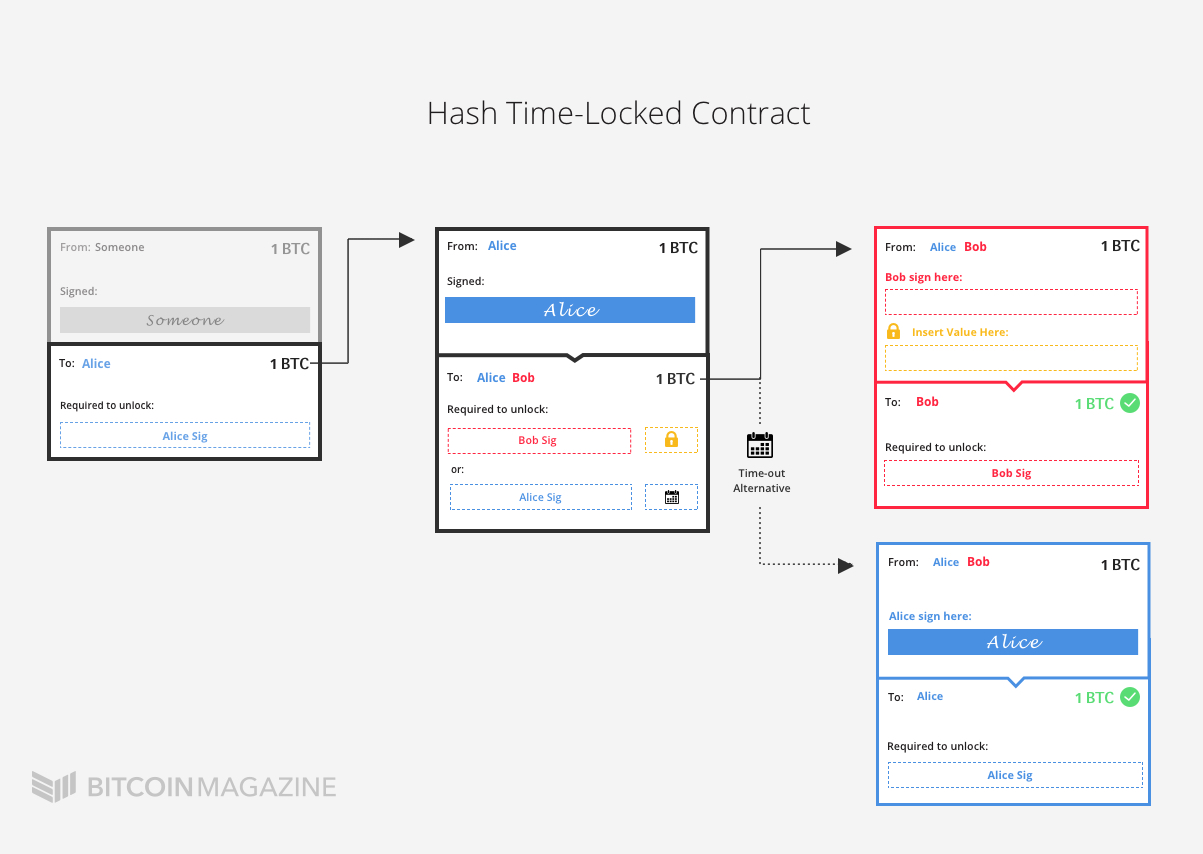
 这笔交易中, 有一个输入,2个输出,输入和输出的地址都是t开头.
这笔交易中, 有一个输入,2个输出,输入和输出的地址都是t开头.